Federated Learning


Introduction
Description
Forecasting electricity consumption accurately is crucial for managing energy resources efficiently, ensuring reliable power supply, and optimizing grid operations. This task is complex, particularly because of the diverse and evolving usage patterns across different households. Usage patterns vary not only across households, but also over time (e.g. number of occupants changes). This leads to what is known as concept drift, which occurs when the underlying data patterns that predictive models have learned change, potentially degrading the model’s performance.
In scenarios where data privacy is paramount and bandwidth is limited, the concept of federated learning emerges as a vital approach. Federated learning allows multiple decentralized entities—such as different households in the case of electricity consumption—to collaboratively learn a predictive model while keeping all training data local. This method avoids the need to transfer large volumes of sensitive data to a central server, addressing significant privacy concerns. However, federated learning environments face significant challenges among which concept drift is a prominent one:
- Dynamic and heterogeneous data sources often lead to concept drift, where the underlying data patterns the model has learned change over time, potentially degrading the model’s performance.
- Limited bandwidth for communication between clients and the central server can hinder the efficiency of model updates and retraining processes.
- Privacy concerns limit the amount and type of data that can be shared between clients, complicating the detection and mitigation of concept drift.
These challenges necessitate advanced strategies for model training and maintenance to ensure that predictive models remain accurate and efficient over time without compromising privacy or incurring prohibitive communication costs.
Business goal
The business goal for this Starter Kit is electricity forecasting in collaborative distributed environments. Specifically, a concept drift mitigation strategy will be applied to cope with the occurrence of concept drift due to the heterogeneous and dynamic nature of electricity usage data. The methodology, called FedRepo, was introduced by Tsiporkova et al. [1] and aims to provide a robust solution that maintains the accuracy and efficiency of the federated models over time, ensuring they adapt to changes in data dynamics while minimising communication overhead.
Application context
The FedRepo methodology is applicable in various settings where data privacy and limited connectivity are major concerns:
- Healthcare: Hospitals and medical institutions can collaborate on developing predictive models or improving diagnostic tools on more diverse data without actually sharing patient data.
- Wearables: User experience of several features (e.g. text prediction) can be enhanced on personal devices without compromising privacy.
- Industrial: Assets manufactured by a third party (e.g. printers) can be used to collaboratively learn predictive models without each customer having to share its data. For example, data from various assets in different settings can be used to predict maintenance needs or optimise performance without exposing individual usage patterns or sensitive business information.
Starter Kit outline
We will first describe the dataset that we will be using for this Starter Kit, which consists of accelerometer data containing six time series signals. Then, we conceptually explain the Swinging Door Trending technique, and apply this on the six signals separately. Afterwards, we apply the technique on the six signals at once, which makes sense since accelerometer signals are often correlated. We then evaluate the results of both compression approaches on a technical level by considering how much they manage to compress the original signals and what is the associated error. Finally, we validate the compression within a concrete application, i.e. event detection.
Dataset
The forecasting of electricity consumption across households is a highly relevant application for this methodology as energy consumption of households obviously is privacy-sensitive. This was demonstrated in [2], where it is highlighted how household energy patterns can reflect socio-economic statuses. Additionally, many factors could cause for concept drift to occur:
- The occupation of the household in terms of its inhabitants
- Replacement of household appliances
- Fluctuations in electricity prices, encouraging more conservative usage during high price periods
- …
The data used is collected by the UK Power Networks led Low Carbon London project (available here). It consists of 5,567 households (given in column consumer) in London representing a balanced sample representative of the Greater London population with a 30-minutes granularity between November 2011 and February 2014. The consumption (in column consumption) is given in kWh. For demonstrating our methodology, we randomly selected 300 households for which we ensured that the data is available until at least 01/2014. For these households, a repository of federated models will be trained in order to forecast the consumption within the next 30 minutes.
FedRepo
The FedRepo algorithm, designed to mitigate concept drift in federated learning environments, is structured around several key principles. These principles ensure that the algorithm dynamically adapts to changes in data distributions across different consumers (households), maintaining the efficacy of the deployed models. In our example on electricity consumption forecasting, we use Random Forest (RF) regressor models for the regression task. Note though, that the approach can be adapted to classification tasks by using RF classifiers and an appropriate performance evaluation metric instead.
Here, we give an overview of the single steps of the FedRepo approach but will elaborate on each step in the remainder of the notebook.
- Local model training: each consumer trains its own RF regressor model locally. This ensures that sensitive usage data is never shared across consumers or with the central node. Only model parameters like the number of trees or the minimum number of samples required to split an internal node are shared with the central node.
- Federated model construction: at the central node, federated cluster models are constructed aggregating the insights from local models trained by a group of consumers.
- Concept drift detection: the performance of deployed federated models is regularly evaluated at the local level. This ensures that the framework is able to detect concept drift when needed.
- Mitigation: if concept drift is detected, several maintenance steps are taken to mitigate its effects. This could include the retraining of local models with recent data.
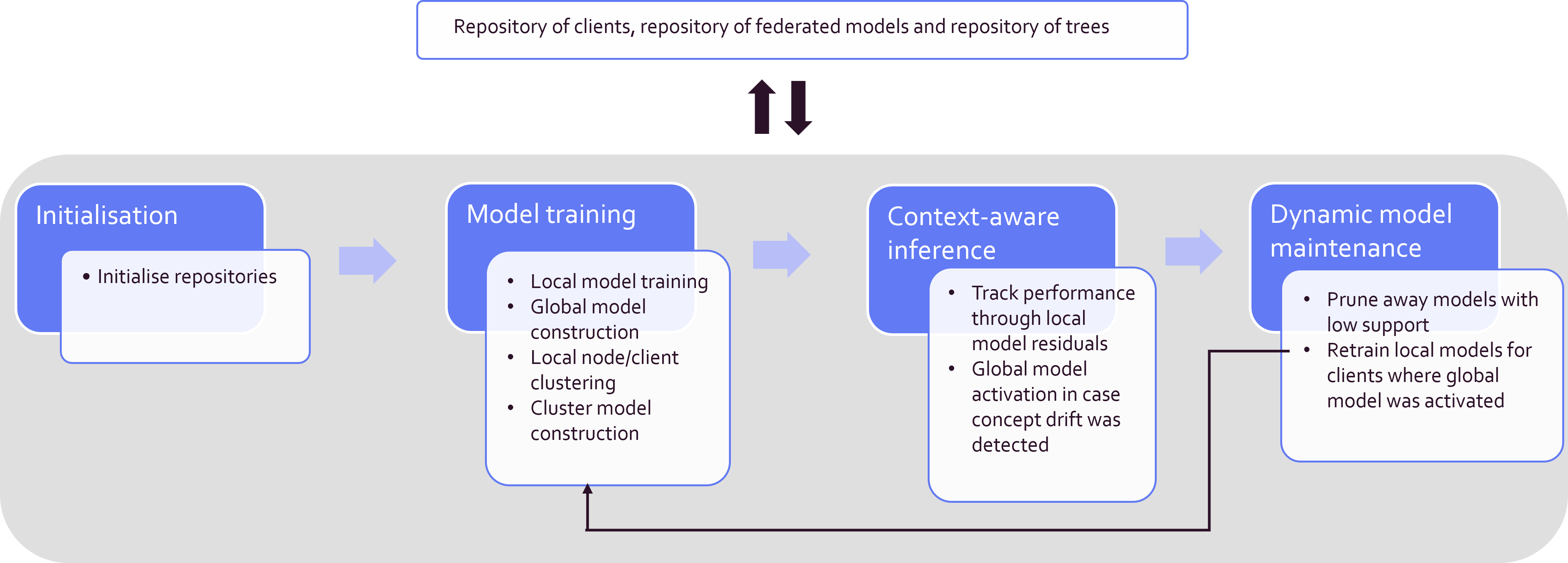
These principles are reflected in the main phases of FedRepo, which are: Initialization, Model training, Context-aware inference and Dynamic model maintenance. These are shown in the image below which gives an overview of the methodology. Throughout the methodology, three repositories (hence the name, FedRepo) kept at the central node are continuously maintained and updated to adapt for concept drift:
- Θ: a repository of workers, which contains at any moment the workers for which new federated models need to be constructed.
- Φ: a repository of global federated random forest models, which contains at any moment the active (deployed) federated models.
- Γ: a repository of tree models, which contains at any moment subsets of trees from local RF models of each worker.
Note that a worker refers to a consumer in this use case, however in other applications it could be any type of clients/devices. In the following, each of the main phases will be discussed one by one and executed on the UK Power Networks dataset.
|
[1] E. Tsiporkova, M. D. Vis, S. Klein, A. Hristoskova, and V. Boeva, “Mitigating Concept Drift in Distributed Contexts with Dynamic Repository of Federated Models,” 2023 IEEE International Conference on Big Data (BigData). IEEE, 15-Dec-2023.
[2] C. Beckel, L. Sadamori, and S. Santini, “Automatic socio-economic classification of households using electricity consumption data,” Proceedings of the fourth international conference on Future energy systems. ACM, 21-May-2013.
[3] M. G. H. Omran, A. Salman, and A. P. Engelbrecht, “Dynamic clustering using particle swarm optimization with application in image segmentation,” Pattern Analysis and Applications, vol. 8, no. 4. Springer Science and Business Media LLC, pp. 332–344, 24-Nov-2005.